
Traffic Sign Detection Kaggle Competition
Traffic Sign Detection Kaggle Competition
In the last assignment of Computer Vision Class at 2016 Fall. We participated in a Kaggle competition with the rest of the class on the The German Traffic Sign Recognition Benchmark. The objective was to produce a model that gives the highest possible accuracy on the test portion of this dataset.
The benchmark is well researched and there are kwown architectures that gets below 1 percent error. I share in this post my experience with different Conv-Net architectures and Torch on HPC of NYU.
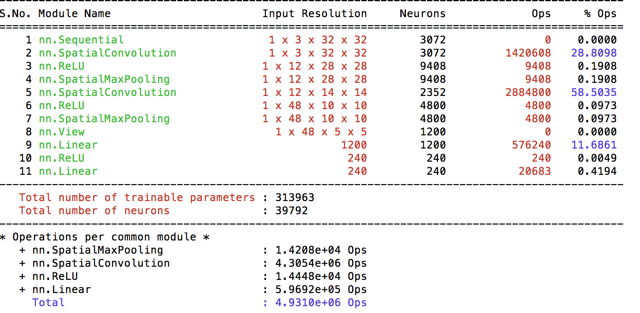
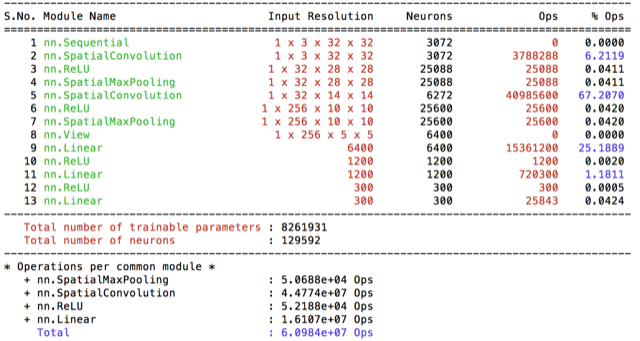
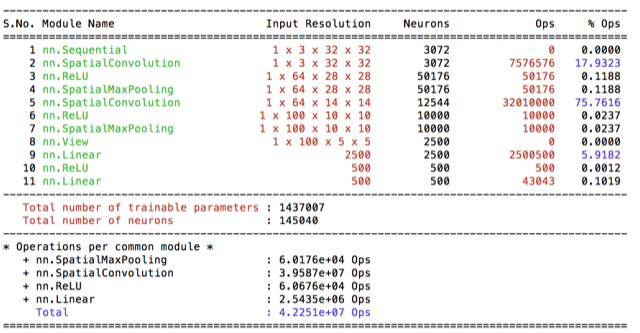
Over one week period I have experimented with different models on HPC. I’ve thought that limited GPU’s are going to be pretty busy and therefore implement my code to work with cpu in a multithread matter. I’ve started by implementing preprocessing separete then the training, such that I don’t preprocess same image twice. I’ve implemented ParallelIterator, however realized that it is not required when you already preprocessed the data and just reading from ram. Therefore haven’t needed it for my experiments. I’ve follow a similar approach to organize my code models/ file includes the models I have used and prepro/ folder includes the preprocesing methods I’ve experimented. I’ve provided the convergence graphs of the models and the operation breakdowns with each model. I’ve used [Lua-profiler] to approximate #operations per model. (https://github.com/e-lab/Torch7-profiling/).
Source code can be found at https://github.com/evcu/cv2016
cifar and basic32
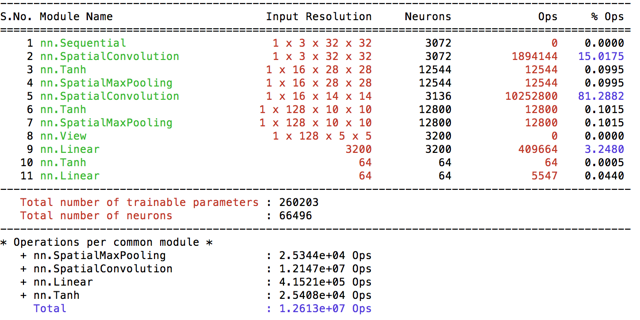
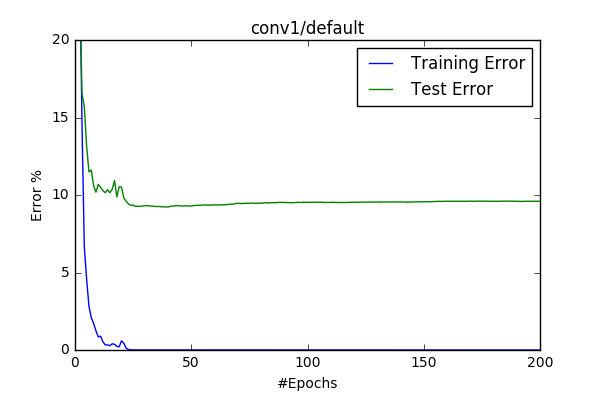
This is the default model given with the starter code. I’ve trained 200 epochs with the default parameters (LR=0.1, momentum=0.9). As I introduced above I’ve implemented preprocessing as a separete process and named the default basic processing(given) as basic32. The algorithm converges quickly, therefore I’ve plot only the first 25 epoch.
- Learning Rate After my first trials I’ve wanted to play with learning rate and see its effects. I’ve change the learning rate up(0.5) and down(0.01). The learning rate seemed to be doesn’t necessearly effect the final output(I got a slight improvement with (0.5). I also observed that if you increase it a lot, it doesn’t converge. However 0.1 seemed to be an appropriate learning rate to me, because when LR=0.01 converge quite slow, but it looks like it has better generalization but converges slowly.
| 0.1 | 0.5 | 0.01 |
|---|---|---|
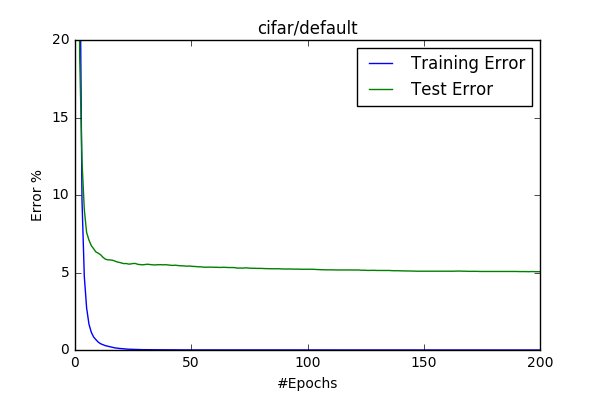 |
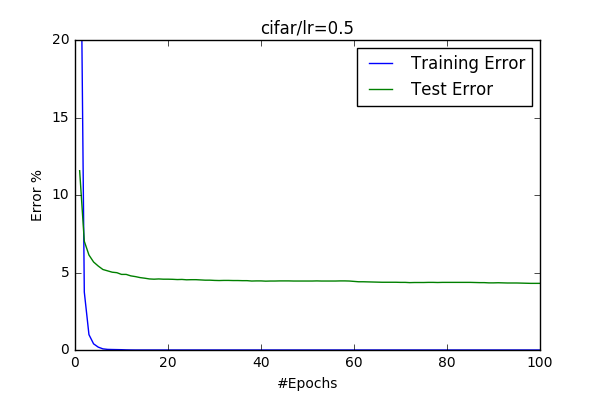 |
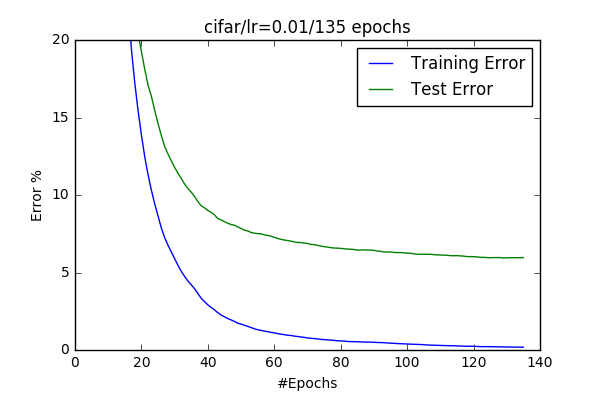 |
- Resampling Data Second I wanted to implement resampling. Since I decided to preprocess the data separete from the training I’ve padded the training data with more samples from each class which has less sample then the class who has maximum samples. At the end the size of the data set increased to 96750 from 39209. I’ve observed an even faster convergence(probably due to increased training-dataset size).
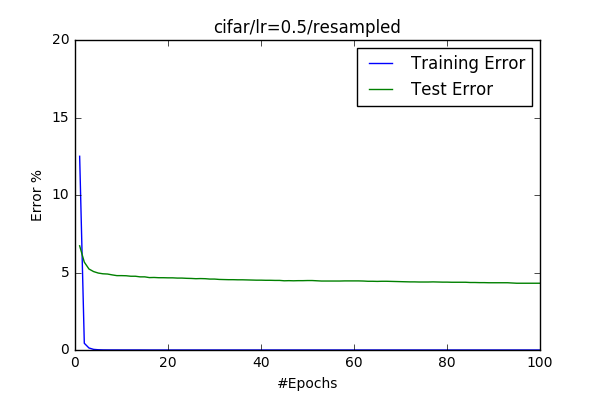
- Changing Momentum Third I wanted to see efect of momentum. I believe that momentum really helps the model to converge properly. But it doesn’t increase the final accuracy enourmously.
| momentum = 0.95 | momentum = 0.75 |
|---|---|
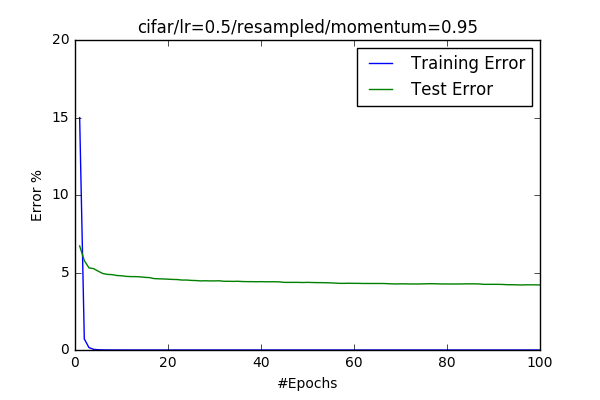 |
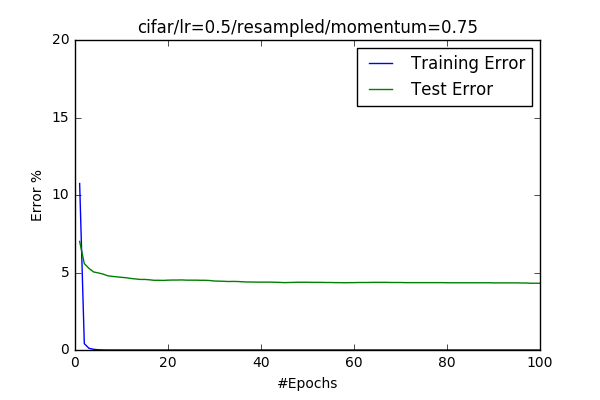 |
-
Multihreading / ParallelIterator I have realized that the original code, preprocesses the images during training at each epoch again and therefore creates a bottleneck. Instead I decided to process the images before training and save it, then read it at each epoch with the iterator. By doing so we are processing the data-set only once, and the iterator only reads/shuffles/do the partition of the data. I’ve implemented parallel-iterator and used
nThrLoadflag to define multiple parallel iterators. However I’ve observed that this reduced the performance and increaased the memory usage considerably. I’ve observed that one thread is fast enough at serving multiple threads(12-16) and therefore stick with the single iterator for the rest of the trainings. -
BEST_ERROR: around 5%
conv1
I wanted to see what happens if I decrease the number of filters in the Conv layer. This choice does make a big difference in terms of total number of parameters, however #operations are around 3 times less. So I’ve trained this model with 0.1 learning rate two times: one with other without resampling. The test accucary dropped drasctically to 90%. Resampling provided %0.5 increase in the accucary.
| w/ resampling | w/o resampling |
|---|---|
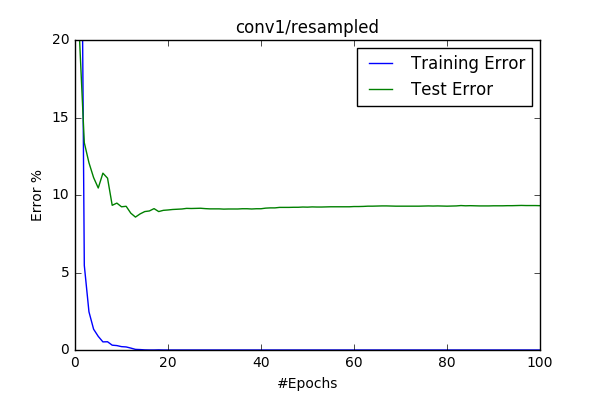 |
 |
- BEST_ERROR: around 9.6%
conv2/3
conv2 | conv3
:————————-:|:————————-:
 |
| 
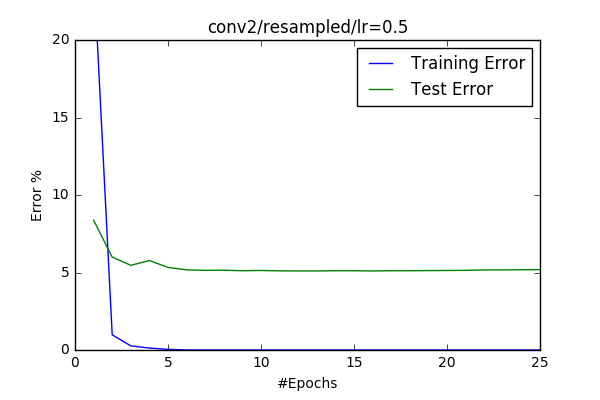 |
| 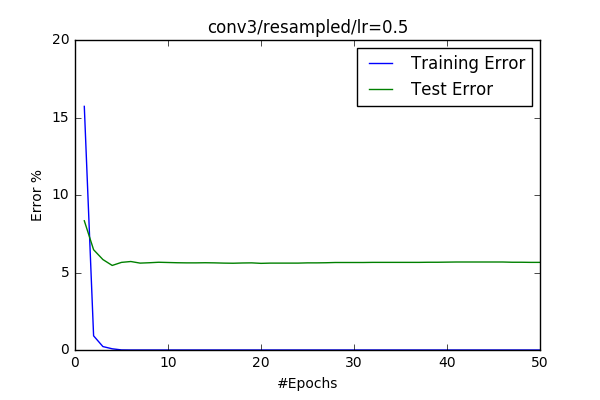
So it gets worst if I make the #filters, why not increasing them. I’ve created 2 new models conv2 having double amount of filters and one extra of fully connected layer. I’ve trained the model and I got pretty much the same result as the base-cifar model gets. conv3 was an experiment making the #filters of the first layer big. I’ve read that it is better if it is a small number and you increase number of filters while decreasing the dimensions through conv-layers. I wanted to check that and the result confirmed the statement. I’ve got an error around %5.6, which is .6% worst then the base-cifar model.
- BEST_ERROR: around 5%
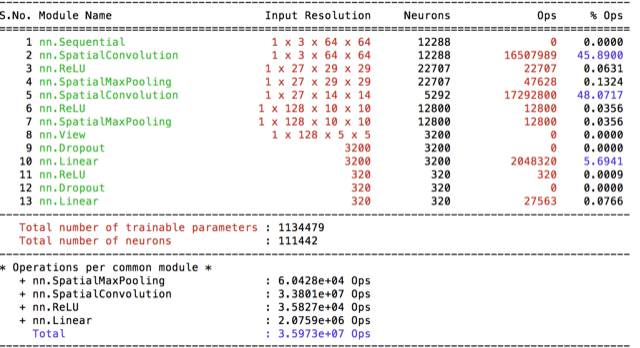
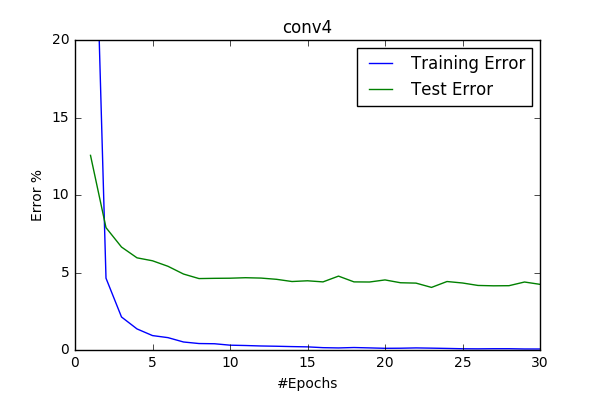
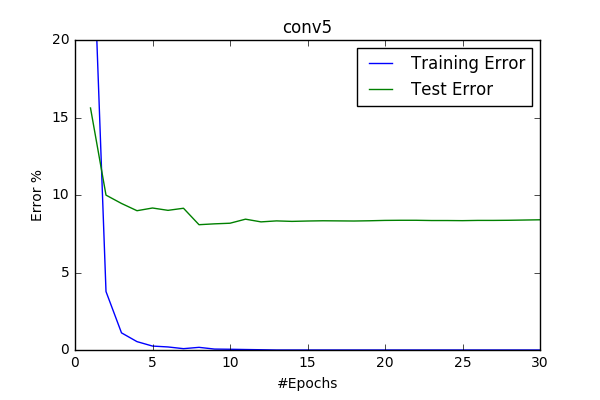
conv4/5/6 and basic64
conv4 | conv5 | conv6
:————————-:|:————————-:
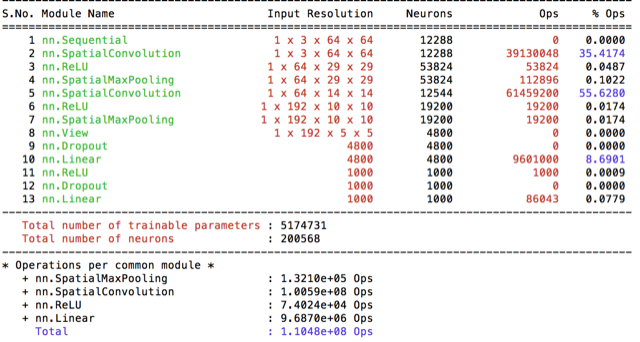 |
| 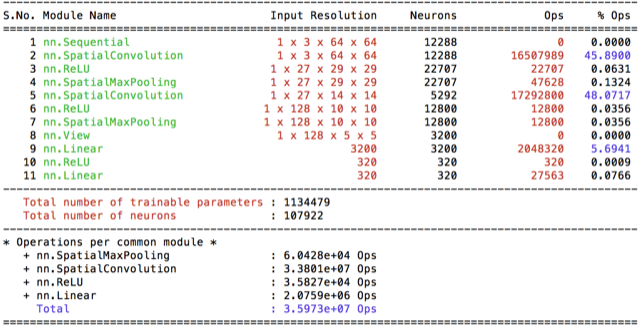 |
| 
 |
|  |
| 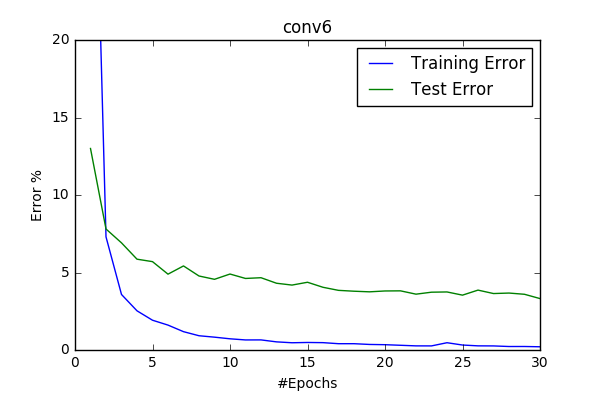
So at this point I decided to increase the input-image size and start scaling images to 64x64 and I’ve introduced model conv4 with it. It does increased my best score by 1%. It was considerably slower then the base model cifar(10x). Therefore I wanted to measure whether the increase was due to the increased #filters or due to the dropout layer. I’ve created two models while decreasing the filter sizes and making the models more plausable to train.
Dropout appeared as being quite important for better accuracy. With the better and faster model conv6 I’ve run 100 epoch and got 2.9%
- BEST_ERROR: around 2.9%
conv7 and norm64
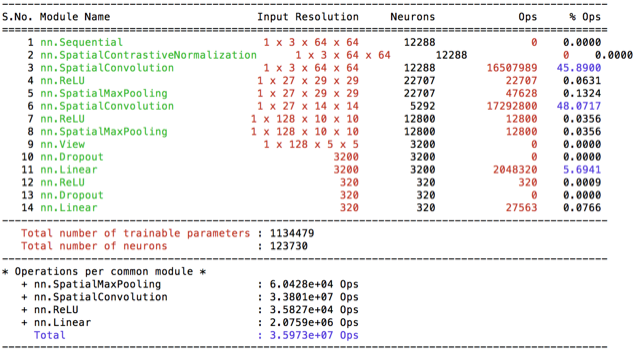
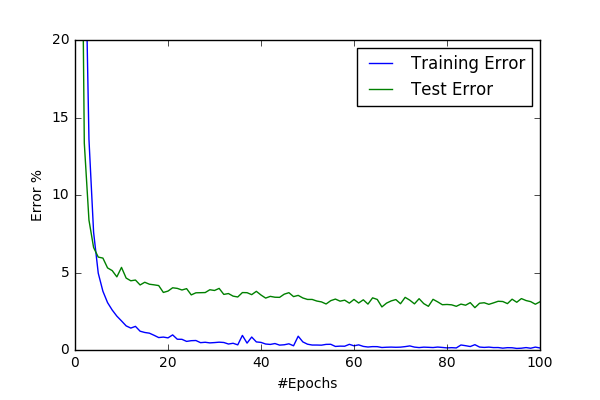
Then I’ve implemented couple of suggested normalization method. First I transformed the images to YUV space and then globally normalized them such that each channel has zero mean and unit variance. I’ve also extented conv6 model with a starting Spatial Contrastive Normalization layer and named the new model suprizingly as conv7. I haven’t obverved any significant difference between norm64(3.2%) and basic64(3%) preprocessing scripts. I’ve start observing oscillations at test error at this point and start thinking of implementing adaptive learning rate.
| conv6/basic64 | conv6/norm64 |
|---|---|
 |
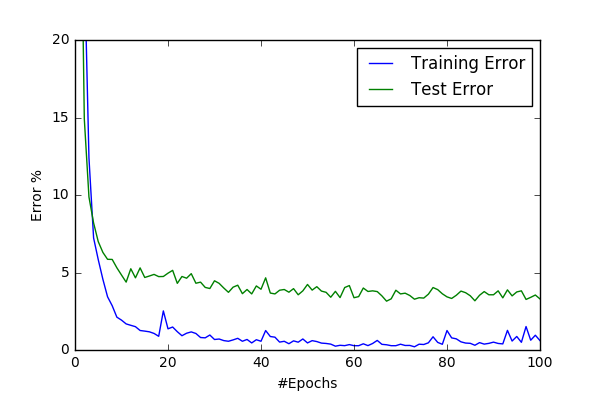 |
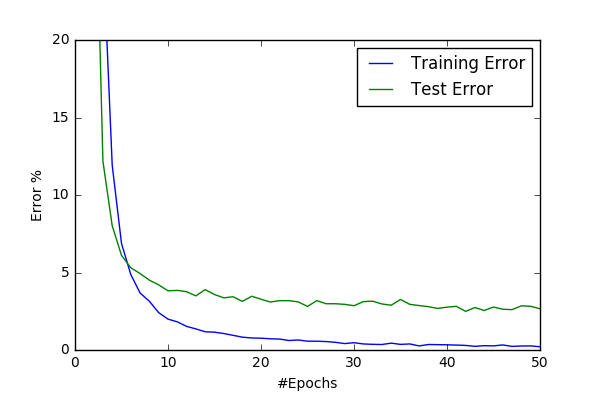
However conv7 gave superior result to conv6 and increased my best result to %97.4
| conv7/basic64 | conv7/norm64 |
|---|---|
 |
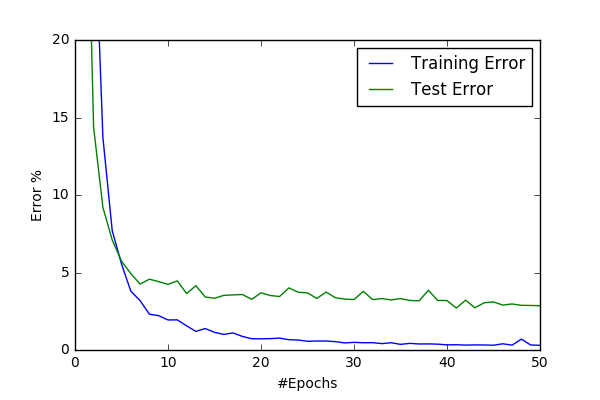 |
- BEST_ERROR: around 2.6%
conv48-1 and cut48/cut48contra
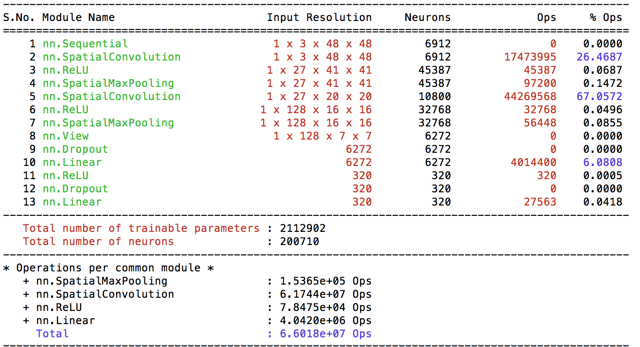
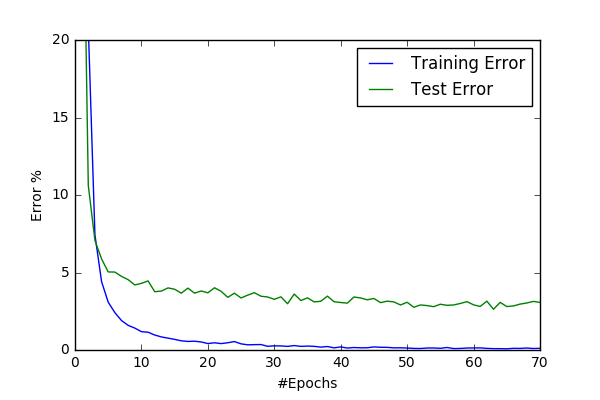
So the deadline was approaching and I want to try more models and try them faster. So I decided decrease my input size to 48. I have adapted the conv6 to the new input size and named as conv48-1 (finally a better naming convention). Then I’ve also decided to implement cropping the images(rectangles are provided with data). I’ve included YUV-transformation and global normalizing as default to cut48. I’ve decided to implement Spatial Contrastive Normalization during preprocessing to prevent repeatitive processing and named the new as cut48contra. I’ve got 0.5% better results with cut48contra then cut48 having the following convergence graphs with learning rate=0.05.
| conv48-1/cut48 (97.2%) | conv48-1/cut48contra (97.7%) |
|---|---|
 |
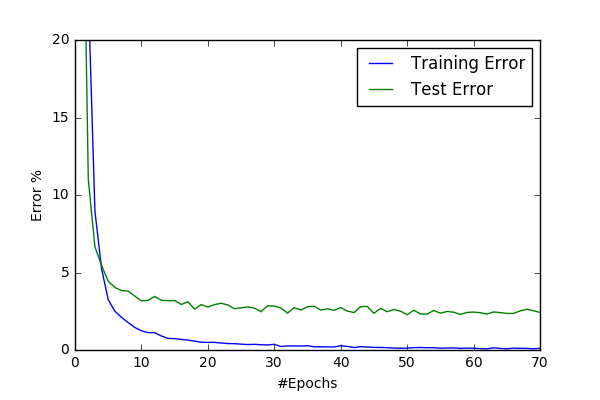 |
After this I’ve exprimented with learning rare and got worst results with LR=0.01. Then I’ve turned resampling on and got a slight improvemnt after 50 epochs ending up the best performance so far
- BEST_ERROR: around 2.2%
conv48-2/3
cconv48-2 | conv48-3
:————————-:|:————————-:
 |
| 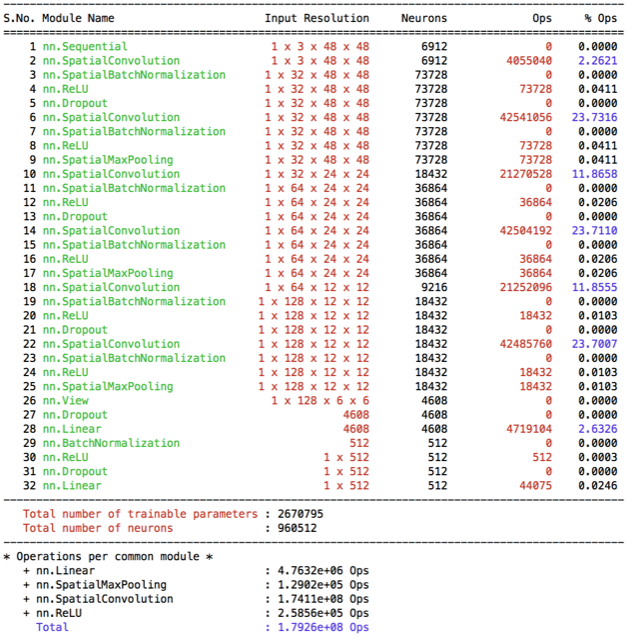
At this point I’ve decided implementing learning rate decay (since it became much more important at this point, error is so small). Along with that, I realized that I did pretty much enough at preprocessing side and decided focusing on the model and got inspired by the VGG-model. I’ve adapted the VGG idea into a new model and ended up with my biggest model conv48-2. Then I’ve decided to replace last 3 VGG-layer with a fully connected layer and reduce the #parameters(by 7) and #operations (by 3). I’ve did a lot of experiments with these two model and also with Learning Rate Decay(LRD). My findings being:
- I’ve got similar results with two models. One reason being I didn’t train
conv48-2more than 70 epoch(1 epoch was taking 15min). - I trained 150 epochs
- LRD=0.1 didn’t give good results. I think it is two big. I’ve got better results when I decreased LRD.
- Resampling didn’t give significant better results for these models. (One problem being, due to my implementation the dataset sizes are different and trainings become incomparable in terms of convergence and #epochs)
- I got my best result in Kaggle with
conv48-3following parameters LR=0.05, LRD=1e-4, without resampling
Below I share convergence graphs for the two models:
| conv48-2 | conv48-3 |
|---|---|
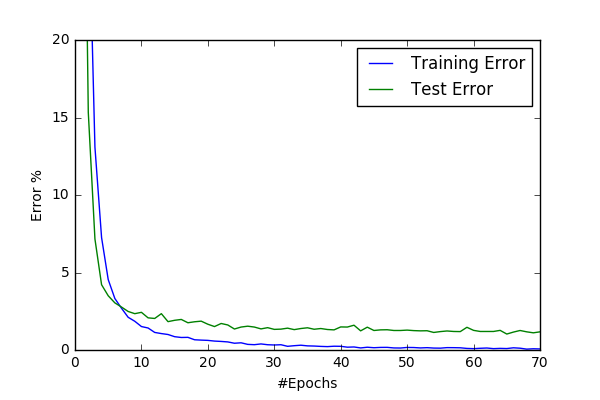 |
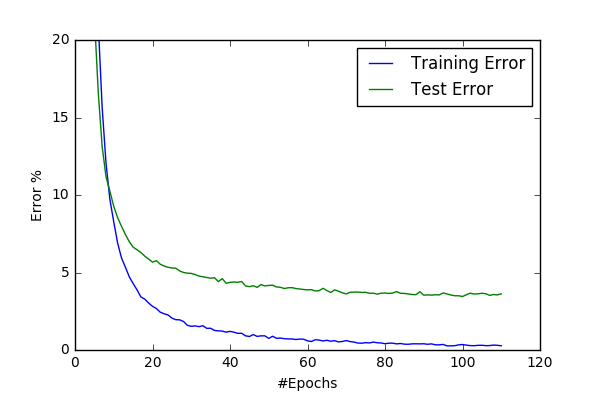 |
- BEST_ERROR: around 0.9%