
Implementing Sparse Networks with MicroGrad
![]()
O lala, time passes fast under quarantine. It has been almost 3 weeks since Andrej Karpathy shared his super light-weight autograd library and me getting exciting about it. Roughly 2 years ago I had a similar mini-project and wrote about it here. After seeing Micrograd and its simplicity I decided to spend some time on it.
Andrej’s implementation works on pure python and the speed is not a concern. I thought maybe we can accelerate it using sparsity :P. Just kidding…
I realized how easy it would be to implement sparse networks if the building blocks are neurons. It literally took me few hours to implement sparse networks and RigL algorithm. I think this is a great demonstration of the power of changing abstractions. The abstractions and tools we have influences our work/research greatly and maybe what we need is a paradigm shift to enable the next big jump in AI. I would vote for neurons as the future building blocks of Neural Networks. But arguing about this is not the goal of this notebook.
Plan
- Checkout Andrej’s implementation of
Valuehere. This is the building block of back-propagation algorithm and it is the simplest autograd engine I’ve seen. - Checkout the demo. At the end of this notebook, we would repeat the same experiment using sparse networks.
- We will implement Sparse network (SparseMLP) which uses the SparseLayer which uses the SparseNeuron.
- Finally we will train our network on a binary classification task. We will observe the failure of regular sparse training and we see how RigL can be used to improve performance considerably.
Defining Sparse Network
Neurons in a layer usually connects to the every neuron in the previous layer. This is because how we define them. We call such networks dense (although I would argue they are sparse, too since they are not connecting bunch of other neurons in other layers.).
On the other hand sparse neurons connect to only a fraction of the neurons in the previous layers and the sparsity of a neuron can be defined as the fraction of neurons it is not connected. So number of connections in a sparse neuron would be defined by,
\[\#connections = \lfloor(1 - sparsity) * \#input\_neurons\rfloor\]Below, we share the implementation of SparseNeuron. It calculates number of connections as defined above and holds the weights in a dictionary self.w using the index of the input neurons as keys.
RigL algorithm, sometimes need to calculate the gradient of the non-existing connections. In order to do that we define self.zero_ws which are populated if the dense_grad=True.
class SparseNeuron(Module):
def __init__(self, nin, sparsity, nonlin=True):
assert 0 <= sparsity < 1
n_weights = math.ceil((1 - sparsity) * nin)
w_indices = random.sample(range(n_weights), k=n_weights)
self.w = {i: Value(random.uniform(-0.1, 0.1)) for i in w_indices}
self.b = Value(0)
self.nonlin = nonlin
self.zero_ws = {}
def __call__(self, x, dense_grad=False):
if dense_grad:
# We need to calculate all gradients therefore introduce zeros.
self.zero_ws = {}
results = []
for i, xi in enumerate(x):
if i in self.w:
results.append(self.w[i]*xi)
else:
self.zero_ws[i] = Value(0)
results.append(self.zero_ws[i]*xi)
act = sum(results, self.b)
return act.relu() if self.nonlin else act
else:
act = sum((wi*x[i] for i, wi in self.w.items()), self.b)
return act.relu() if self.nonlin else act
def parameters(self):
return list(self.w.values()) + [self.b]
def __repr__(self):
return f"{'ReLU' if self.nonlin else 'Linear'}Neuron({len(self.w)})"
Defining Larger Building Blocks and Loss
Next we define SparseLayer, SparseMLP and the loss function. Nothing special here except the regular neurons are replaced by sparse neurons. SparseMLP expects a list of sparsities in addition to the hidden layer sizes.
class SparseLayer(Module):
def __init__(self, nin, nout, sparsity=0, **kwargs):
self.neurons = [SparseNeuron(nin, sparsity, **kwargs) for _ in range(nout)]
def __call__(self, x, dense_grad=False):
out = [n(x, dense_grad=dense_grad) for n in self.neurons]
return out[0] if len(out) == 1 else out
def parameters(self):
return [p for n in self.neurons for p in n.parameters()]
def __repr__(self):
return f"Layer of [{', '.join(str(n) for n in self.neurons)}]"
class SparseMLP(Module):
def __init__(self, nin, nouts, sparsities):
sz = [nin] + nouts
self.layers = [SparseLayer(sz[i], sz[i+1], sparsity=sparsities[i],
nonlin=i!=len(nouts)-1) for i in range(len(nouts))]
def __call__(self, x, dense_grad=False):
for layer in self.layers:
x = layer(x, dense_grad=dense_grad)
return x
def parameters(self):
return [p for layer in self.layers for p in layer.parameters()]
def __repr__(self):
main_str = '\n'.join(str(layer) for layer in self.layers)
return f"MLP of [\n{main_str}\n]"
# loss function
def loss(model, batch_size=None, dense_grad=False):
# inline DataLoader :)
if batch_size is None:
Xb, yb = X, y
else:
ri = np.random.permutation(X.shape[0])[:batch_size]
Xb, yb = X[ri], y[ri]
inputs = [list(map(Value, xrow)) for xrow in Xb]
# forward the model to get scores
scores = list(map(partial(model, dense_grad=dense_grad), inputs))
# svm "max-margin" loss
losses = [(1 + -yi*scorei).relu() for yi, scorei in zip(yb, scores)]
data_loss = sum(losses) * (1.0 / len(losses))
# L2 regularization
alpha = 1e-4
reg_loss = alpha * sum((p*p for p in model.parameters()))
total_loss = data_loss + reg_loss
# also get accuracy
accuracy = [(yi > 0) == (scorei.data > 0) for yi, scorei in zip(yb, scores)]
return total_loss, sum(accuracy) / len(accuracy)
Our Sparse Network
Here we create a sparse network. Note that there is only 2 input dimensions and we want to use them both. Therefore we set the sparsity to 0 for the first layer. Last layer has a single output neuron, therefore we set its sparsity to a lower value than the middle layer.
These sparsities are selected arbitrarily, feel free to play with them.
Let’s create this model and train it with SGD.
np.random.seed(1337)
random.seed(1337)
static_sparse_model = SparseMLP(nin=2, nouts=[16, 16, 1], sparsities=[0.,0.9,0.8]) # 2-layer neural network
print(static_sparse_model)
print("number of parameters", len(static_sparse_model.parameters()))
MLP of [
Layer of [ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2)]
Layer of [ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2)]
Layer of [LinearNeuron(4)]
]
number of parameters 101
TRAIN_STEPS = 400
for k in range(TRAIN_STEPS):
# forward
total_loss, acc = loss(static_sparse_model)
# backward
static_sparse_model.zero_grad()
total_loss.backward()
# update (sgd)
learning_rate = 1 - 0.9*k/TRAIN_STEPS
for p in static_sparse_model.parameters():
p.data -= learning_rate * p.grad
if k % 20 == 0:
print(f"step {k} loss {total_loss.data}, accuracy {acc*100}%")
print(f"step {k} loss {total_loss.data}, accuracy {acc*100}%")
step 0 loss 0.9999118995994747, accuracy 50.0%
step 20 loss 0.9501034046836242, accuracy 50.0%
step 40 loss 0.3029776283757716, accuracy 87.0%
step 60 loss 0.297169433748757, accuracy 87.0%
step 80 loss 0.29289542954897096, accuracy 88.0%
step 100 loss 0.2931921490672611, accuracy 87.0%
step 120 loss 0.2989848931028508, accuracy 88.0%
step 140 loss 0.2911950144271784, accuracy 87.0%
step 160 loss 0.29066315530929493, accuracy 88.0%
step 180 loss 0.2899413473514984, accuracy 88.0%
step 200 loss 0.29011181298721433, accuracy 88.0%
step 220 loss 0.2897383548597768, accuracy 88.0%
step 240 loss 0.289301900462062, accuracy 88.0%
step 260 loss 0.2886158754721536, accuracy 87.0%
step 280 loss 0.2881950427716646, accuracy 88.0%
step 300 loss 0.28796501931513896, accuracy 87.0%
step 320 loss 0.28737672236751133, accuracy 88.0%
step 340 loss 0.28752147018854757, accuracy 88.0%
step 360 loss 0.28687039533784287, accuracy 88.0%
step 380 loss 0.28676645061703504, accuracy 88.0%
step 399 loss 0.28654023971513226, accuracy 88.0%
Difficulty of Training Sparse Networks.
Sparse training is difficult. This has been reported by many, including the Lottery Ticket Hypothesis. RigL is one of the recent dynamic training algorithms (others include (SNFS, SET, DSR). It changes how the neurons are wired during the training dynamically and by doing so improves the training of sparse networks.
Here is a summary of how RigL updates connections:
1) Calculate dense gradient, which enables us to obtain the gradient of non-existing connections using SparseNeuron.zero_ws.
2) For each layer obtain existing and candidate parameters.
3) If no parameters to update, continue with the next layer.
4) Pick candidate connections with highest gradient magnitude.
5) Pick existing connections with lowest magnitude.
6) Replace least magnitude connections with new ones that have high expected gradient.
from micrograd.rigl import top_k_param_dict
def rigl_update_layer(model, update_fraction=0.3):
# (1) Calculating dense gradient
total_loss, acc = loss(model, dense_grad=True)
model.zero_grad()
total_loss.backward()
for layer in model.layers:
n_weights = 0
# (2) For each layer obtain existing and candidate parameters.
candidate_params, params = [], []
for j, neuron in enumerate(layer.neurons):
n_weights += len(neuron.w)
# Decide connections to grow (pick top gradient magnitude).
candidate_params.extend([(p, i, j) for i, p in neuron.zero_ws.items()])
params.extend([(p, i, j) for i, p in neuron.w.items()])
# Done with zero_ws delete them.
neuron.zero_ws = {}
# (3) If no parameters to update, skip this layer
n_update = math.floor(n_weights * update_fraction)
if n_update == 0:
# Not updating
continue
# (4) Obtain candidate connections with highest gradient magnitude.
top_grad_fn = lambda p: abs(p.grad)
top_k_candidate_params = top_k_param_dict(candidate_params, n_update, sort_fn=top_grad_fn)
# (5) Obtain existing connections with lowest magnitude.
least_magnutide_fn = lambda p: -abs(p.data)
bottom_k_params = top_k_param_dict(params, n_update, sort_fn=least_magnutide_fn)
# (6) Replace least magnitude connections with new ones with high expected gradient.
for (p, i, j), (_, i_new, j_new) in zip(bottom_k_params, top_k_candidate_params):
del layer.neurons[j].w[i]
p.data = 0.
layer.neurons[j_new].w[i_new] = p
np.random.seed(1337)
random.seed(1337)
rigl_model = SparseMLP(2, [16, 16, 1], [0., 0.9, 0.8])
N_TOTAL = 400
for k in range(N_TOTAL):
# forward
total_loss, acc = loss(rigl_model)
# backward
rigl_model.zero_grad()
total_loss.backward()
# update (sgd)
learning_rate = 1 - 0.9*k/N_TOTAL
for p in rigl_model.parameters():
p.data -= learning_rate * p.grad
if k % 20 == 0:
print(f"step {k} loss {total_loss.data}, accuracy {acc*100}%")
if k != 0: rigl_update_layer(rigl_model, update_fraction=learning_rate*0.3)
step 0 loss 0.9999118995994747, accuracy 50.0%
step 20 loss 0.9501034046836242, accuracy 50.0%
step 40 loss 0.31005307891543676, accuracy 86.0%
step 60 loss 0.29439281503845477, accuracy 87.0%
step 80 loss 0.29081179132781054, accuracy 88.0%
step 100 loss 0.2876179472370331, accuracy 88.0%
step 120 loss 0.2844175041217564, accuracy 86.0%
step 140 loss 0.3083420441792058, accuracy 85.0%
step 160 loss 0.2796200131507172, accuracy 88.0%
step 180 loss 0.270197735972451, accuracy 89.0%
step 200 loss 0.2548698443690211, accuracy 90.0%
step 220 loss 0.2519338433937867, accuracy 90.0%
step 240 loss 0.14442011238413255, accuracy 96.0%
step 260 loss 0.22868415294455974, accuracy 96.0%
step 280 loss 0.06459693547356511, accuracy 97.0%
step 300 loss 0.061831516333362764, accuracy 100.0%
step 320 loss 0.04567886755653798, accuracy 99.0%
step 340 loss 0.04156236561415438, accuracy 100.0%
step 360 loss 0.03462738757482692, accuracy 100.0%
step 380 loss 0.031153761540187855, accuracy 100.0%
Results
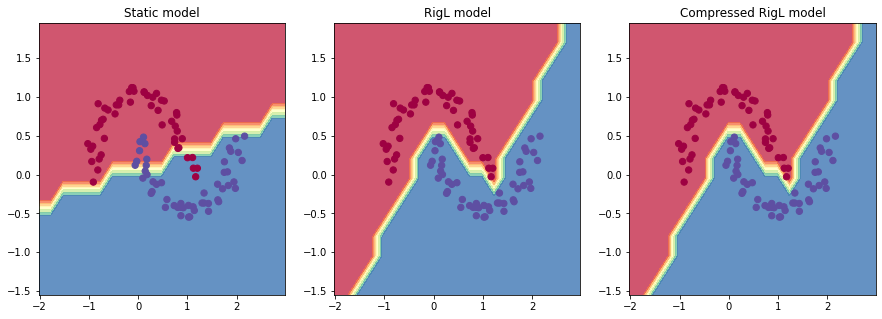
RigL obtains 0.031 loss with 100% acc vs static training obtains 0.287 with 88% acc.
Visualizing the connectivity of the model after the RigL training reveals interesting insights. We see that the available connections are used by few important neurons and many neurons internal neurons are discarded.
For example below, neurons 2_3 and 2_1 have the most of the connections of the second layer. Other active neurons (2_4 and 2_2) have a single incoming connections. All the remaining neurons are dead, which means they don’t have any incoming or outgoing connections and therefore they can’t effect the output. We can safely remove dead units. Let’s do that.
draw_topology(rigl_model, rankdir='TB')

Stripping Dead Units
Removing dead units we are left with a compact 10,4,1 (compared to 16,16,1) architecture.
from micrograd.rigl import strip_deadneurons
compressed_rigl_model = strip_deadneurons(rigl_model)
print(compressed_rigl_model)
draw_topology(compressed_rigl_model, rankdir='TB')
MLP of [
Layer of [ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2), ReLUNeuron(2)]
Layer of [ReLUNeuron(5), ReLUNeuron(1), ReLUNeuron(7), ReLUNeuron(1)]
Layer of [LinearNeuron(4)]
]

Visualizing the decision boundries
Let’s (yet again) use Andrej’s code to visualize the decision boundaries.
# visualize decision boundary
h = 0.25
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Xmesh = np.c_[xx.ravel(), yy.ravel()]
Zs = []
inputs = [list(map(Value, xrow)) for xrow in Xmesh]
for m in [static_sparse_model, rigl_model, compressed_rigl_model]:
scores = list(map(m, inputs))
Z = np.array([s.data > 0 for s in scores])
Zs.append(Z.reshape(xx.shape))
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
for i, key in enumerate(['Static model', 'RigL model', 'Compressed RigL model']):
plt.axes(axs[i])
plt.contourf(xx, yy, Zs[i], cmap=plt.cm.Spectral, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title(key)
Acknowledgements
Most of this notebook is based on Andrej Karpathy’s original demo at micrograd repo. So I would like to thank Andrej for open-sourcing and sharing his code.